
To Forecast, Or Not To Forecast?
20 November, 2017 - Stefan de Kok
Demand forecasting is under pressure. Supply chains are getting ever more fragmented, through globalization and portfolio expansion, causing the traditional forecasting methods that used to work somewhat adequately to deteriorate to levels that do more damage than good. Recognizing this, new schools of thought are appearing that aim to remove the dependency on forecasting. There is a lot to be said for this objective. Why indeed would you want to forecast something with uncertainty if you could just know it with certainty?
In this vein, great strides have been made with demand driven approaches such as demand sensing and DDMRP (Demand-Driven Material Requirements Planning). The former aims to remove latency and downstream bullwhip in the supply chain by capturing demand closer to the end consumer. In the extreme, Point-of-Sale (or POS) demand sensing, captures bar-code scans at the cash register. This means demand is exactly known in fine granularity days or weeks before it is received as a sales order. DDMRP drives improvement from that point back in a different way. It strategically places inventory buffers within the company to minimize effective lead times and streamline flow of product. It avoids forecasts, aiming to drive all replenishment from sales orders. In this way it removes uncertainty and reduces the bullwhip effect within the internal supply chain. In a perfect world, we can drive our entire supply chain using these approaches and never need a forecast.
But this is not a perfect world. Demand sensing only buys a limited extra amount of information lead time, and likewise DDMRP has a limit to how much it can reduce replenishment lead time. As a result, forecasts are still needed. But the same known weaknesses of traditional forecasts that spawned the innovation of these demand driven approaches also tend to blind-sight the minds behind the innovations to both the need and the means of how to create complete solutions that incorporate the forecasts they reject. This article aims to shed some light of where and how this can and should be done.
Where Are Forecasts Needed?
Before presenting how forecasts can complement demand-driven approaches, I will first briefly describe where it is needed. There are roughly three categories of interaction between forecast-based approaches and forecast-less approaches:
- On the boundary between tactical and operational planning processes
- On the boundary between medium-term and short-term planning horizons
- In determining buffer levels within operational planning processes
Tactical plans may pass planned shift patterns, sourcing decisions, capacity availability, strategic inventory buildup, and so forth to the operational processes. Naturally a lot of the inherent uncertainty of future demand, which these plans are driven by is still there, just transformed to be less recognizable as such. Proper integration between these planning levels may lead to a welcome higher efficiency related to common but small outliers, and significantly lower risk exposure to rare but large outliers.
In the next category, for some part of the immediate future all sales orders may be known, and it is possible to use them to drive replenishment. For the far future, no sales orders are known, and any plans in that time range need to be driven purely by a forecast. But somewhere in the middle, some but not all sales orders are known. This transition phase is where the biggest errors in forecasting processes occur. Whenever replenishment lead times are greater than customer order lead times (also known as customer tolerance times) this phase is where the biggest errors are introduced whenever forecasts are either ignored or naively consumed.
Finally, buffer levels exist to protect against variability and uncertainty from both demand and supply. You could forecast what those will look like in future, or you could take some historical average, also known as a naive forecast. Either way, consciously or unconsciously, you will use a forecast to set these buffer levels. It should also be clear that these forecasts need to be specific to individual items at the individual location where the buffer is located. Using aggregate behavior will not suffice. A full understanding of the uncertainty is crucial to ensure efficient use of working capital whilst guaranteeing the buffering capacity to some acceptable level.
What Kind of Forecast is Needed?
The demand-driven approaches have all been inspired out of necessity: the realization that the known forecast techniques were sorely inadequate to the task. As is often the case with innovation, different groups try to find a solution to the same problem in completely different directions. Where the demand-driven approaches gave up on forecasting altogether, probabilistic forecasting was conceived on the notion that forecasting is necessary, but that traditional approaches went about it the wrong way. Both these alternatives have been gaining traction and proving themselves with similarly sized impact in different segments of the market. It is our opinion that combined they will be able to provide much larger value still.
Probabilistic forecasting was inspired by the realization that that you cannot predict uncertain behavior with precise, exact numbers. The mainstream forecasting market built a huge house of cards on this fundamentally flawed premise. Albert Einstein is attributed with the famous quote that you should "make everything as simple as possible, but no simpler". Statistical forecasting made their foundation too simple. As a result it has needed to resort to excessive levels of complexity to compensate. Probabilistic forecasting is based on a less simple foundation: treating future values as ranges of possible values, each with a probability of occurring. As a consequence everything built on it can remain much simpler, allowing for greater scalability and better results. My previous article "Probabilistic Forecasting vs Statistical Forecasting" explains the concepts in more detail.
The combination of demand-driven and probabilistic can succeed where demand-driven and statistical are destined to fail. In my previous article I exposed the key difference in this regard:
- Statistical forecasting is precise but not accurate
- Probabilistic forecasting is accurate but not precise
The Demand Driven Institute acknowledges this as the key problem with forecasts. They promote and demonstrate economist John Maynard Keynes' notion that it is "better to be roughly right than to be precisely wrong".
Demand-driven approaches are both precise and accurate, but only available for a limited time range. Forecasts cannot be both, but they extend the time range to any desired horizon. It is easy to demonstrate that when you forego accuracy the results deteriorate dramatically. However, when you maintain accuracy and forego precision instead, it just means you need to incorporate the known level of precision into your buffer levels and replenishment signals to extend the time range over which you can plan. The below graph sketches where each of the three approaches add value, and what happens when they are combined:
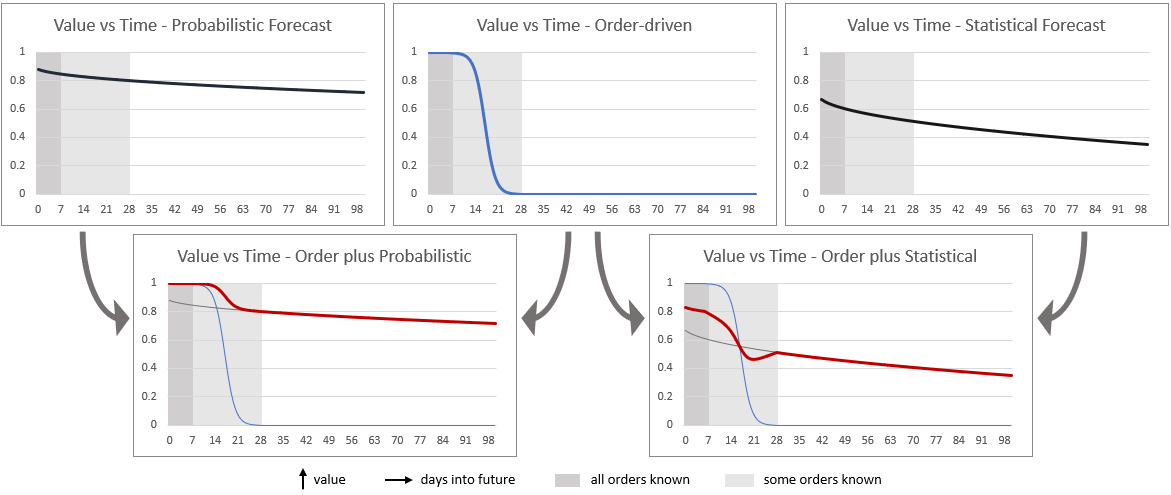
All value assessments and time ranges are anecdotal. When driving purely on orders the value is complete in the time range that all orders are known. As we enter the time range where not all orders are yet known, value reduces until it reaches zero where no orders are known. Forecasts on the other hand provide a lower value, but retain most of that value in time. The difference in value between probabilistic and statistical forecast is based on the general 50%+ reduction in error achieved by the former over the latter (traditional MAPE). If we were to use proper probabilistic accuracy metrics, such as TPE (explained in Foresight Magazine), the gap is typically much larger.
The two bottom charts indicate what happens when orders are allowed to consume forecast. Probabilistic forecasts retain all the value of the known orders and provide additional value for the gap between known and unknown. Statistical forecasts however subtract value. Since these are expressed as exact period-wide numbers the consumption of orders from forecast is completely unknown. Rudimentary rules are used, ranging from simple subtraction of orders from forecast, to exceedingly complex rules with interlaced forward-backward consumption. None are based on current reality. If you were to measure residual forecast you will observe that it has a strong bias and indeed in some time range its accuracy is lower than the original statistical forecast. I will explore this behavior in more detail in a future article.
By virtue of operating at the most granular level of detail a probabilistic forecast can match orders to the destination. This means no order can ever consume forecast for another customer location. And due to its probabilistic nature it is known how likely additional orders will be received, allowing an unbiased residual forecast. Depending on how far ahead materials need to be ordered and staging and production commenced one has the option to use the certainty of known orders or be forced to accept some level of uncertainty beyond that time horizon. The charts below illustrate how uncertainty can be minimized by combining order-driven and probabilistic forecasts, again anecdotal.
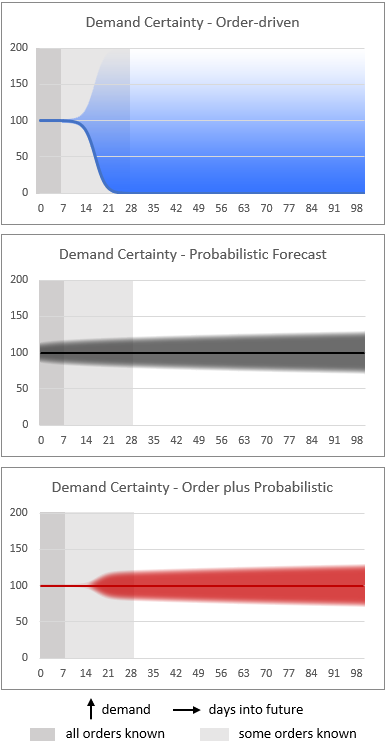
The vertical axis here depicts demand level, and shaded areas illustrate uncertainty.
How Can Forecasts be Blended into Order-Driven Processes?
The benefits of order-driven planning are that it is relatively simple, allowing it to be adhered to via a methodology, and that it is accurate and precise within a short time window. The benefits of probabilistic planning are that it drives greater efficiency and retains accuracy for a long time horizon. However, to do so, it requires sophisticated mathematics processed by appropriate software. We envision a progression of increasing sophistication starting from a low-budget, methodology-based approach to get quick wins and train the people to adhere to processes that are aligned across the company. Once this has stabilized, start increasing efficiency of working capital and customer service levels, through better math. Finally, as more parts of the planning system landscape are able to process the richer probabilistic input, streamline their integration, with the goal to drive overarching objectives into operational details, whilst allowing the latter the largest degree of freedom for maximum efficiency.
These are roughly the steps in this progression:
- On the planning and execution side use of pure DDMRP (inventory positioning, buffer sizing, planning, visualization, collaborative execution), possibly as part of a Demand-Driven Adaptive Enterprise (DDAE) model or of some other historically grown planning landscape. The key parts are inventory positioning and getting the organization to adhere to overarching processes. These will persist throughout the progression. On the forecasting side step 1 is a probabilistic forecasting engine for increased accuracy, but not yet utilizing its other benefits in downstream planning processes.
- Inject sensed demand as a type of order into the DDMRP planning process. This could be any downstream demand from VMI outflow all the way to Point-of-Sale (POS) scans at store cash registers if available. This demand is purer demand than sales orders (closer to the end consumer), that are absent any bullwhip-inducing distortions from orders as they are passed down the supply chain. Also, this demand is known earlier, ranging from days to multiple weeks earlier than direct sales orders, allowing a demand-driven response even when replenishment lead times exceed customer tolerance times. In almost all cases this will be a mixed-mode solution, since each customer will be at a different stage of maturity and collaboration of such data to their vendors.
- Replace Average Daily Usage (ADU) with a cumulative probabilistic forecast value. The big benefit here of using a probabilistic forecast is that it is robust against outliers, mitigating the bullwhip effect. It therefore retains the benefit of a smoothed naive forecast, without the downside of its low accuracy around known future extremes (such as promotions, holiday seasons, etc). This is the least intrusive adjustment to a pure DDMRP approach.
- Replace buffer levels with ones determined in a probabilistic MEIO (Multi-Echelon Inventory Optimization). Skip deterministic MEIO, it adds little value at this point. Ideally new levels are provided using the zone concept for reporting and visualization purposes. At this step the largest mathematical error remaining from implicit use of a forecast is removed. This is still relatively low change management impact, since it can be done as an add-on, simply replacing some numeric values but none of the inner calculations. At this step significant efficiencies are gained.
- Use a probabilistic residual forecast to trigger replenishments under some conditions where not all orders are known. This is a first step where core tenets of DDMRP would be violated but also where the value of the charts in the previous chapter starts coming into play. It would be utilized where the alternative (not doing anything) would be worse. This would be any scenario where replenishment lead times are greater than customer tolerance times, and preparing for any new product introduction, promotions, extreme seasonal spikes or short seasons (such as fashion), new store or account additions, and so forth, where waiting would mean missing great opportunities or inability to deliver due to capacity and lead time constraints. Here bullwhip is reduced beyond DDMRP's horizon of customer tolerance times.
- Replace the net flow equation with a probabilistic version. Where earlier steps could be retrofit, at this point the system driving DDMRP itself will need to incorporate the probabilistic mathematics. So this will be a big step requiring full backing of the Demand Driven Institute. Note that such a probabilistic version is not yet developed at this time; it is just a vision. All the above will become part of the same holistic vision, rather than mere tweaks to a different vision.
- Replace integration of target values with target ranges between various planning processes. Instead of sending exact values for individual items from tactical to operational planning processes, send acceptable ranges for groups of items and periods of time. When time, material, resources, or other capacities are expected to be scarce and items need to compete for these, this approach allows tactical decisions to drive operational plans without hamstringing them to inefficiency. This is a first step where additional benefits of probabilistic systems can be utilized in a larger planning landscape where some other systems may not be probabilistic.
- Replace integration of deterministic ranges of values with probabilistic ranges between various planning processes. At this point, all sending and receiving systems need to be probabilistic. The full benefit of probabilistic planning is obtained across the company's controlled portion of the supply chain. Functional silos are truly removed, since not just numbers are passed over the fence, but the full scope of options and their ramifications. Plans across the board are stabilized, greater efficiency of cost, and greater customer service levels are achieved. When done fully, loops are closed, allowing direct feedback of management decisions, not just guesses or wishful thinking of cost and benefit, but accurate estimates of these plus the likelihood they may occur.
Notice that in terms of process very little changes in this progression. Only the mathematics and the integration change. It is one of Wahupa's core tenets that software should be a pure enabler. It should never dictate a company to follow a prescribed best-practice process or logic. If software does dictate a process that feels unnatural, forced or inefficient, it means it is not the right software for your business.
But in this progression more sophistication becomes available to the planners and decision makers. This sophistication can be used to streamline processes, to visualize problems in intuitive ways not possible before, or to do so preemptively before they materialize, where otherwise the only option would be to react. Just because the above does not enforce any change in process, does not mean it should not be done...
It is our believe that forecasting is here to stay. It will get better, more accurate, more actionable. It will get less complex, but more sophisticated under the hood in order to be simpler for the driver to use and trust. Where traditionally forecasting has been the agent of instability, probabilistic forecasting will become the tool to return to stability.